The design and implementation of SCALP has been very different from the design and implementation of other processors. SCALP's objective has not been purely performance as is the case with most other designs; rather it has been largely motivated by power efficiency. SCALP's architecture is novel: it replaces one of the fundamental entities - the register bank - with an alternative model for result-operand communication. Finally the implementation is unusual, using asynchronous logic.
With all of these areas of change it is not surprising to find that SCALP does not perform perfectly throughout. Despite this, much can be learnt from this implementation about how one should, and how one should not, design a microprocessor for power efficiency. This final chapter summarises the features of the SCALP architecture and implementation and considers ways in which it could be improved upon. These and other possible future areas of work are described, including ways in which SCALP's good points could be incorporated into more conventional processors.
Previous low power processors have applied mainly low level power efficiency techniques as they need to maintain code compatibility with previous implementations of the architecture. In contrast SCALP concentrates on higher level techniques, specifically code density, parallelism and asynchronous implementation.
High code density is beneficial to power efficiency because the energy consumed in the memory system is in proportion to the amount of code that must be fetched. Areas where code density increases can be made are identified as the encoding of register specifiers, which can take up half of the bits in a conventional instruction set, and the use of variable rather than fixed length instructions.
By increasing the amount of parallelism in a circuit and reducing the supply voltage it is possible to operate with the same throughput but with reduced power consumption. Many conventional processors employ parallelism in the form of pipelining and superscalar execution in order to increase performance. As the potential maximum parallelism in the processor increases it becomes increasingly difficult to exploit; techniques such as forwarding, branch prediction, and out of order issue must be used. These all lead to increases in the complexity of the control logic which will potentially increase power consumption and reduce performance. It seems desirable to move some of the responsibility to the compiler in order to make simpler control logic possible.
Implementation using asynchronous logic has advantages in terms of performance and power efficiency compared with synchronous implementation, especially in systems with a variable workload where dynamic supply voltage adjustment is possible. Asynchronous logic lends itself well to the implementation of pipelines and parallel functional units until non-local communication such as forwarding is considered. For reasonable performance without locally synchronous behaviour a technique called conditional forwarding is required. Conditional forwarding is only possible if the instruction set indicates how the result of an instruction will be used in the instruction producing the result itself. This is referred to as explicit forwarding.
The SCALP architecture incorporates many of the features suggested by the preceding paragraphs. Most importantly SCALP does not have a global register bank; rather instructions specify destinations for their results in terms of the functional unit input queue to which the result should be sent. Source operands are implicitly taken from these queues. In this way SCALP requires only three bits per instruction to indicate the flow of data through the program, compared with up to fifteen bits for a conventional processor.
One problem with the explicit forwarding mechanism is that when the result of an instruction is used by an instruction beyond a branch the destination cannot be statically encoded into the instruction. In this case the result must be sent to the register unit and written into a register, and subsequently read from the register when its use is known. A second problem is that SCALP provides a fairly inefficient mechanism for sending results to more than one destination. These effects mean that SCALP requires more instructions than a conventional processor. The result is an overall code density that is no better than a conventional processor such as the ARM.
SCALP has five functional units (ALU, Register, Load/Store, Move, Branch) and uses variable length instructions. To simplify the instruction issuer the instruction length and functional unit information is made as simple as possible to decode. In particular the instructions have only two possible lengths and for the longer instructions all control information is contained within the first part. Instructions are decoded and issued in groups and a control field for each group indicates which parts of the group contain short and which long instructions.
SCALP is the first known example of a superscalar processor to be implemented using asynchronous logic. The implementation to a gate level VHDL model has been sucessful and is supported by a set of software tools. The design has been carried out almost entirely by hand as the techniques used are relatively new and any automatic tools are still experimental.
The implementation uses a four phase asynchronous signalling protocol with bundled data. The datapath is generally similar to synchronous datapaths but adders make use of completion detection. The control logic uses a macromodular style with largely speed independent interconnections of modules. The modules use a bounded delay timing model internally.
Despite the architectural efforts to reduce the complexity of the instruction issue problem the issuer is a large part of the processor taking up 39 % of the gate count. Despite its large size neither it nor the result forwarding network limit performance. Performance is generally limited by three factors: branch latency, dependencies between instructions and contention for functional units. The branch latency is around 8 times as long as a typical instruction execution period without branches, so 8 potential instruction executions are lost for each branch.
The asynchronous logic style used is relatively slow compared with synchronous implementations; typical cycle times for functional units are around 50 gate delays. This seems to be a consequence of the macromodular design style which leads to very sequential "flowchart-like" circuits.
Evaluation of the SCALP architecture has shown it to have some weaknesses, leading to worse code density than had been expected. However it is certainly not clear that the fundamental idea of replacing register-based communication with explicit forwarding is hopeless. This section considers how the weaknesses in the architecture can be put right.
Section 7.8 revealed that SCALP's explicit forwarding mechanism is flawed in the way that it deals with results being passed to destination instructions beyond branches. Furthermore the mechanism also does not deal very well with results that are used more than once as explicit duplicate operations are required.
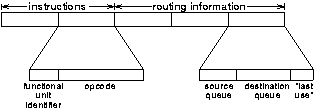
The solution to these problems must be to separate in the instruction stream the routing of results from the instructions that produce those results. In this way the results can be routed after the results of any branch instructions are known. Furthermore this approach lends itself to multiple use of results as more than one piece of routing information can be associated with each instruction. One encoding scheme is shown in figure 8.1.
In the scheme shown in figure 8.1 the instruction stream is divided into instructions and routing information. The format of the instructions is similar to the existing SCALP instructions except that there are no destination bits. Each item of routing information indicates a source queue (i.e. a functional unit output) and a destination queue (i.e. a functional unit input). To allow for multiple uses of results it incorporates an additional bit. This may mean either "this is the last use of this result" or "this is the first use of a new result from this queue".
This scheme has similarities to the Transport Triggered Architecture described in section 5.6.3 which is encouraging as it is known that this architectures makes a good compiler target.
To evaluate this encoding the inner loops of the example programs described in section 7.1.1 have been rewritten in the new format. The static code sizes for these inner loops are given in table 8.1. It can be seen that the new encoding increases code density by around 20 %.
Program SCALP SCALP with separate result routing Instrs Immeds Bits Instrs Immeds Moves Bits shading 10 0 130 7 0 8 118 wc 13 2 195 10 2 9 180 strtree 16 0 208 10 0 10 160 qsort 31 0 403 19 0 16 286 sumlist 8 0 104 5 0 6 86 Geometric mean 186 153Disappointingly even with this modification SCALP's code density remains significantly lower than can be achieved with some variants of conventional instruction sets such as ARM Thumb (section 2.1.3).
Some areas in which the SCALP implementation performs poorly and could be improved have already been identified; specifically the pipeline throughput would be substantially increased if branch prediction were used and the speed of the asynchronous control circuits could be increased by employing more sophisticated implementation techniques.
Section 7.3.2 reports that the performance of the processor is significantly affected by the lack of branch prediction. A conventional branch prediction scheme could be adapted for use with SCALP's asynchronous implementation, and indeed one scheme has already been applied to an asynchronous processor: AMULET2 makes use of an associative memory to find new PC values.
For SCALP a technique used by conventional superscalar processors and described in [JOHN91] might be more appropriate. This scheme stores branch prediction information in the instruction cache. Each cache line would store one FIG plus additional information to indicate which cache line contains the next FIG. By giving the cache line number rather than an address the need to perform an associative lookup in the cache is removed, making the cache potentially faster and more power efficient. The cache lines must also store information indicating which instructions within the FIG will not be executed because they lie after a taken branch or before the branch target. This scheme allows for only one prediction per FIG.
The implementation of prediction checking and incorrect prediction recovery would be influenced by the asynchronous nature of the design. Incorrect prediction recovery is similar to exception recovery and as was mentioned in section 5.5 SCALP's unusual transient state makes this process different from conventional processors. There are various ways in which SCALP could implement prediction checking and recovery:
In this scheme the instruction issuer does not issue instructions until the branch unit has confirmed that all preceding instructions have been correctly predicted. This is very similar to the current scheme where other functional units' tokens are not allowed to overtake the branch unit's token.
In this scheme the instruction issuer issues instructions from beyond branches but the functional units do not start to execute them until the branch prediction has been confirmed. When the prediction has failed the functional units are responsible for deleting the wrong instructions from their instruction queues. This scheme takes less time between the branch outcome being confirmed and other functional units starting execution.
In this scheme functional units execute instructions before the branch outcome is known and subsequently the result network or operand queues discard results that come from incorrectly executed instructions. This scheme permits the highest performance but in order to recover from incorrect predictions it is necessary for functional units to keep copies of their old operands until the instructions have been confirmed.
[JOHN91] claims that the speedup attributable to branch prediction is around 30 %. This agrees with estimates made on the basis of the results in section 7.4; if the periods during which no functional unit is active were eliminated the speed of the SCALP example programs would be increased by 34 %.
As was noted in section 7.6 the speed of SCALP's asynchronous functional units is poor in comparison with the speed of synchronous processors. This can be attributed at least in part to the macromodular style of the asynchronous control logic in these blocks.
There are two techniques that can be applied to help improve this performance. One option is to move from the current style of largely speed independent interconnections of macromodules to a less constrained more hand-crafted style. The AMULET1 and AMULET2 designs for example use this approach and obtain better performance than SCALP. The disadvantage of this technique is that the design takes more effort, is more susceptible to errors and requires more careful verification.
The other possibility is to make greater use of automatic optimised synthesis. Tools exist that are able to synthesise asynchronous circuits from formal specifications such as state graphs or signal transition graphs. Examples include Forcage [KISH94], Assassin [YKMA95], Meat [DAVIA93], and ATACS [MYER95]. At the present time these tools and our understanding of their behaviour are not suficiently developed to make them of significant use. In future implementations provided by these tools have the potential to avoid the highly sequential nature of the macromodular circuits used by SCALP.
Although the instruction issuer does not in general limit the performance of the processor, if the functional units could be accelerated the issuer could become a bottleneck. The speed and complexity of the instruction issuer are made worse by two aspects of its functionality: variable length instructions and branches. In light of this it is worth considering removing some features to simplify and speed up the design.
Branch instructions are indispensable, and indeed the need for branch prediction makes this part of the instruction issuer more complex. While it is attractive from this point of view to consider eliminating variable length instructions it is important to note that they contribute greatly to increasing code density.
One possibility is to simplify the way in which variable length instructions are dealt with. The idea is to make all instructions the same length, but to have for example "ALU instruction instructions" and "ALU immediate instructions". From the point of view of the instruction issuer these instructions are for different functional units and are dealt with as such, making a much simpler and hence faster (though larger) instruction issuer possible. At the functional unit inputs the immediate fields are matched with the instructions in the same way that operands from the operand queues are matched.
Although the processor as a whole is pipelined the individual functional units are not. In most cases there is no point in adding internal pipelining as the units are internally very simple; the register bank for example would be hard to pipeline. One exception is the load/store unit. Adding internal pipelining to this unit so that address calculation is carried out first and then the main memory access is carried out would be beneficial to performance and would not add greatly to complexity.
Section 8.2 shows SCALP's explicit forwarding mechanism can be improved upon; yet the changes described give only a relatively small improvement that still fails to make SCALP competitive with conventional instruction sets in terms of code density. This suggests that any future design may do better by moving towards a more conventional architecture.
On the other hand the Transport Triggered Architecture indicates that a similar system can operate efficiently. The key to understanding this area must be the development of a compiler and the analysis of substantial benchmark programs. A SCALP compiler and other software tools must be a priority.
In terms of implementation it would be very worthwhile to investigate more highly optimised forms of asynchronous circuit generation.
The power efficiency benefit of SCALP's asynchronous implementation has not been proved. This is because the power efficiency benefits of asynchronous implementation are largely dependent on the application; specifically asynchronous logic saves power when the workload is variable and more so if the supply voltage can be adjusted. In a fixed benchmark situation such as measuring the power consumed in executing a loop of a benchmark program asynchronous logic should not be expected to outstrip a conventional synchronous design. To demonstrate and measure the benefit it is necessary not only to build a microprocessor but also to build the hardware and software of a real system executing an application which makes variable demands on the processor.
SCALP attempts to increase power efficiency by means of parallelism. It does so while executing a single instruction stream in similar way to conventional superscalar processors. The parallelism possible with this approach is known to be limited, and it is probable that for much greater parallelism and hence much greater power efficiency a different form of parallelism would be preferable. These other forms, such as message passing or shared memory multiprocessors, have the disadvantage that algorithms must be recoded to take advantage of them. This may be the cost of increased power efficiency.
It can be argued that the greatest challenge facing computer architects is not how to build good new architectures but rather how to apply new implementation techniques to existing instruction sets, maintaining code compatibility. This is most clearly seen in the world of 8086 compatible processors where the huge effort put in to new implementations makes up for the technical inferiority of the underlying instruction set architecture. It is interesting to consider whether the SCALP ideas could in some way be applied to more conventional instruction sets.
A hybrid processor could be constructed as follows: the programmer-visible instruction set is a conventional register-based one. This code is read into the instruction cache as normal. During its first execution the processor detects dependencies between instructions that need forwarding and stores this explicit forwarding information back into the cache with the code. On subsequent executions this information activates explicit forwarding mechanisms to increase the performance of the code.
For an asynchronous processor this approach would provide the benefits of conditional synchronisation and bring out the potential performance of the asynchronous pipelines. On the other hand because of the conventional instruction set any code density benefit would be lost.
This work ends on a mixed note. There are several areas of related work that suggest that the ideas underlying SCALP are sound ones:
On the other hand the SCALP implementation has not performed as well as had been hoped. It can be seen that SCALP's explicit forwarding mechanism is flawed but improvements proposed in this chapter do not make a dramatic improvement. It can also be seen that it is easier to implement a highly parallel system for a special purpose computation, as in the InfoPad, than for a general purpose processor.
In conclusion asynchronous parallel processors offer the possibility of increased power efficiency, but they cannot achieve this using conventional instruction sets and architectures. One alternative architecture has been proposed and evaluated. Although not hugely successful the SCALP architecture points to possibilities for future asynchronous superscalar low power processors.