


Next: Appendices Important
Up: A Primer on Probability
Previous: Likelihood of Data from
Inferring Probability Distribution from Data -- The Bayesian
Approach
In section ![[*]](http://www.cs.man.ac.uk/applhax/latex2html/icons.gif/cross_ref_motif.gif) , it was shown how to compute a
single estimate for a discrete probability. This estimate could differ
from the true value, it is simple the most likely value. Thus, we only
know the value of
, it was shown how to compute a
single estimate for a discrete probability. This estimate could differ
from the true value, it is simple the most likely value. Thus, we only
know the value of 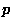 probabilistically. Bayesian methods provide a
way of getting the entire probability distribution for , not just
the most likely value. This approach is explained here. This is an
advanced topic, and is an area of considerable current research.
probabilistically. Bayesian methods provide a
way of getting the entire probability distribution for , not just
the most likely value. This approach is explained here. This is an
advanced topic, and is an area of considerable current research.
Thomas Bayes (1763) asked the inverse question from that discussed in the
previous section. In the above we asked, given a probability
distribution, what is the likelihood of a set of data. Bayes asked the
question, given a set of data, what can be said about the probability
distribution from which it came. Formally, if 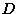 represents the data
and
represents the data
and 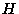 represents some hypothesis about a probabilistic process which
generated this data, the question being asked is what is the
probability of the hypothesis given the data
represents some hypothesis about a probabilistic process which
generated this data, the question being asked is what is the
probability of the hypothesis given the data 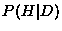 ? Bayes rule can
be used to convert this to the problem above
? Bayes rule can
be used to convert this to the problem above
The conditional probability 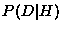 is the probability of a set of
data given a know process which is often straight-forward to
calculate (and was discussed in the previous section). The quantity
is the probability of a set of
data given a know process which is often straight-forward to
calculate (and was discussed in the previous section). The quantity
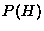 is called the prior - it is the probability of the
hypothesis independent of the data. The probability of the data
is called the prior - it is the probability of the
hypothesis independent of the data. The probability of the data 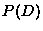 can be thought of as normalisation and calculated from
can be thought of as normalisation and calculated from
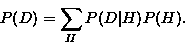
- Example:
- You may have heard the pessimistic adage ``dropped toast
always lands buttered side down''. Suppose you test this. You drop 10
pieces of toast, under controlled conditions of course, and find that
it lands butter side down 3 times out of the ten. What is the
probability that a dropped piece of toast lands butter side down?
Clearly, this is a binomial (Bernoulli) process. The probability of
the toast landing butter side down is , but you don't know
. Bayes formula can be used to calculate the probability
distribution or given this data. A question is, what should we use
as the prior? One possibility is to use our prior belief. Perhaps we
believe in the absence of data that the expected value should be 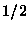 in which case we could use some distribution which has mean and
variance which is a measure of our confidence in this prior
belief. Another possibility is assume that all s are equally
likely,
in which case we could use some distribution which has mean and
variance which is a measure of our confidence in this prior
belief. Another possibility is assume that all s are equally
likely,
We will use this here (there are arguments against use
of a uniform prior, but we shall ignore them as technicalities). Since
it is a binomial process,
Using Bayes Rule with a uniform prior and normalising, we get a
probability distribution for
In general, if we drop the toast 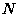 times and it lands butter side
down
times and it lands butter side
down 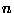 time, Bayes' rule with the uniform prior gives
time, Bayes' rule with the uniform prior gives
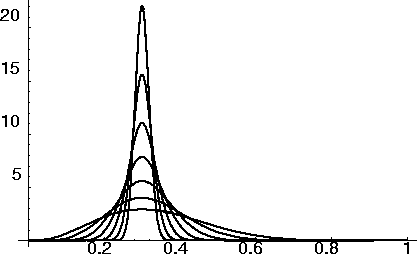
The figure below shows 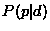 for
for
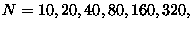 and
and
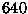 and
and 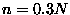 (of course in a real experiment, the measured mean
would fluctuate even dropping toast was truly binomial with
(of course in a real experiment, the measured mean
would fluctuate even dropping toast was truly binomial with
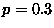 ). For all values of the distribution is peaked around
, of course. As the number of trials increases, the
distribution becomes more and more sharply peaked around this value.
). For all values of the distribution is peaked around
, of course. As the number of trials increases, the
distribution becomes more and more sharply peaked around this value.
Figure:
The probability distribution for for different sample sizes. As the sample size increases, the distribution becomes increasingly sharp. The maximum likelihood estimate is at the peak of the distribution.
 |
Can we conclude from this data that toast always lands butter side
down? From this data, you could infer that . This is the most
likely value; choosing it would a maximum likelihood method. The
Bayesian approach gives you a probability distribution for . Thus,
we could ask, how likely is it that
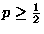 , that is, how
likely is it that dropped toast is more likely to land butter side
down. This likelihood could be computed from
, that is, how
likely is it that dropped toast is more likely to land butter side
down. This likelihood could be computed from
For 10 trials, 3 landing butter side down, this is about 11%. Thus,
we would not reject the hypothesis ``Dropped toast is more likely to
land butter side down'' at the 95 % level. However, if there were 20
trials of which 6 landed butter side down, 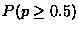 is about 4
%; with that data we could reject this hypothesis at the 95 %
level.
is about 4
%; with that data we could reject this hypothesis at the 95 %
level.
Next: Appendices Important
Up: A Primer on Probability
Previous: Likelihood of Data from
Jon Shapiro
1999-09-23