The reason why RISC processors avoid variable length instructions is that they are more difficult to decode than fixed length instructions. This is especially true when a superscalar processor needs to decode more than one instruction at once.
Figure 2.1 shows how two fixed length instructions can be decoded in parallel. In contrast figure 2.2 shows how five variable length instructions in the same total number of bits must be decoded (the solid lines indicate instruction boundaries, the dotted lines indicate boundaries between parts of the same instruction). Because it cannot tell in advance where the boundaries between instructions lie the decoder must consider the instruction parts serially, making the operation significantly slower.
Figure 2.1: Decoding Fixed Length Instructions

Figure 2.2: Decoding Variable Length Instructions

There are ways in which decoding variable length instructions can be made easier. The simplest modification is to ensure that the first part of each instruction contains all of the control information to indicate the total length of the instruction. In this case the decoder can operate more quickly as shown in figure 2.3.
Figure 2.3: More Efficient Variable Length Instruction Decoding

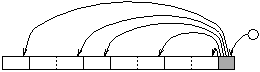
A more radical approach is indicated in figure 2.4. Here a "control field" is associated with each group of instructions. The control field is decoded first and indicates the layout of the instructions within the group to the decoder. The decoder is therefore able to decode all instructions in parallel once the control field has been decoded, making the decoding process nearly as fast as the fixed length instruction decoding. This is the technique used by SCALP.
Figure 2.4: Variable Length Instruction Decoding with a Control Field
2.1.2 Register Specifiers
RISC processors typically use up to about half of the bits in their instructions to represent register numbers. When other techniques such as less redundant opcode encodings and variable length instructions are used this fraction grows more significant. It is important to be able to reduce this factor in order to increase overall code density.
Simply reducing the number of registers is not a solution. Compilers are able to use 32 registers effectively and if the number is reduced the number of load and store instructions is increased.
Reducing the number of register specifiers per instruction is a strong possibility. It is common to find that the destination register is the same as one of the source registers; this was quantified in [ENDE93] (see appendix A) and is summarised in table 2.2. This form of encoding is known as a 2-address encoding rather than a 3-address encoding. Table 2.2 shows that in around one third of instructions one register specifier can be eliminated and a 2-address instruction used. Line 6 of table 2.1 indicates that this can lead to a 5 % code density increase.
Table 2.2: Frequency of 2-address instructions in SPARC code
Instruction category Example % of instructions No register specifiers Branch 19.7 One register specifier Move immediate 12.0 Two register specifiers, equal ADD R1,R1,#1 25.6 Two register specifiers, not equal ADD R1,R2,#1 32.4 Three register specifiers, two equal ADD R1,R1,R2 5.8 Three register specifiers, not equal ADD R1,R2,R3 4.4 Total potential 2-address instructions 31.4Using 2-address instructions is a way of exploiting the locality of register specifiers: if a particular register is given by one register specifier in an instruction then there is an increased chance that it is given by another register specifier in the same instruction. This idea of locality can be taken further. It can be observed that if a register is used in one instruction it has an increased chance of being used by preceding or following instructions.
It is very common for the result that has been computed by one instruction to be used by the immediately following instruction. By referring to "the result of the last instruction" in shorthand rather than by giving its register number a significant code density increase can be obtained. Table 2.3 summarises measurements of this property made in [ENDE93] (see appendix A).
Table 2.3: Frequency of Last Result Re-use
Instruction category % of instructions A: Use the result of the previous instruction 43.8 B: As A, but excluding branch instructions that use the boolean result of a preceding compare 29.4 C: As B, and the value used is not used by any subsequent instructions 20.6Line 7 of table 2.1 indicates that code density can be increased by 5 % by using an instruction encoding which indicates last result reuse in shorthand.
Line C of table 2.3 suggests how this idea can be taken further. Many instructions use the result of the previous instruction and that result is subsequently never used again. In this case it is not necessary for either instruction to provided a register specifier to refer to this value; both may use shorthand. Line 8 of table 2.1 indicates that both forms of shorthand together provide an 8 % code density increase.
It is possible to go further and to allow instructions to refer to the results of other preceding instructions, leading to further code density improvements. This idea forms the basis of the "explicit forwarding" mechanism used by SCALP which is described in chapter 5.
2.1.3 Previous High Code Density Processors
Conventional RISC processors have relatively poor code density due to their regular fixed length instruction format. In comparison the preceding generations of CISC processors made use of a more dense variable length instruction encoding.
In addition to the CISC processors a number of other architectures have increased code density. This section considers three processor designs; D16 and Thumb use 16-bit RISC-like instructions whereas the transputer uses a variable length stack based instruction set.
D16
[BUND94] proposes a 16-bit RISC-like instruction set called D16. This is based on DLXe which is in turn very similar to the MIPS architecture. Comparisons are made between the code density and power efficiency of D16 and DLXe.
D16's instruction set is relatively simple with only five instruction formats. The instructions specify at most two register specifiers and can access 16 registers.
The dynamic code density of D16 is found to be around 70 % higher than that of DLXe. However as the 16 bit instruction set contains less redundancy than the conventional instruction set, more bits on the instruction fetch bus change per cycle. For D16 on average 3.88 bits change per byte of instruction; for DLXe 2.85 bits change. This means that the 70 % code density increase leads to a power efficiency increase on the instruction fetch bus of only around 30 %.
Thumb
Thumb [ARM95] is an extension to the ARM architecture that extends the instruction set to include a set of 16-bit instructions. These 16 bit instructions are dynamically translated to ARM 32 bit instructions during decoding.
The Thumb instruction set is complex with 19 different instruction formats. Most operations use a two address format and can access 8 registers. The standard 32 bit ARM instruction set is available when necessary; for example the Thumb instruction set contains no floating point instructions.
The motivation for Thumb is to increase code density so that ROMs in embedded applications may be smaller, and so that performance can be increased when the processor is connected to a byte or 16 bit wide instruction fetch bus. The reduced instruction fetch requirement also leads to increased power efficiency. Thumb's code density is around 50 % higher than the standard ARM processor.
Transputer
The transputer [MITC90] is an unusual processor with two key features that lead to increased code density.
Firstly the execution model is based on a stack rather than a register bank. Most instructions receive their operands from and write their results to a three entry stack. Other data must be stored in memory, though a small memory is integrated with the processor making this relatively efficient. Memory accesses may be relative to a workspace pointer.
Secondly short variable length instructions are used. Instructions are multiples of one byte long. The most common instructions using only implicit stack addressing without immediate values are encoded in a single byte; less common instructions and immediate values are encoded using "prefix instructions".
2.2 Datapath Activity
Conventional RISC processors normally have a 32 or 64 bit wide datapath consisting of register bank, ALU, shifter, multiplexors, latches etc. This datapath works efficiently when it is processing quantities of this full width such as addresses but many of the values dealt with by a program are significantly narrower than this. Examples include characters which are encoded by only 8 bits and booleans which require only one. When a 32 bit datapath is used to operate on these smaller quantities much of the power used is wasted.
The solution is to add operations to the instruction set that operate on small quantities. When executing these instructions the processor need only activate a part of the datapath.
The power benefit of the reduced datapath activity must be balanced against the reduced code density resulting from the additional width information in the instructions. SCALP chooses the simplest possible scheme with each instruction using a single bit to indicate whether it operates on byte or word quantities.
Many earlier CISC processor architectures included datapath operations of more than one width. In some cases these features lead to complications when advanced implementations of these architectures were considered. Consider the following example: