This chapter investigates the idea that increased parallelism can be beneficial for power efficiency, and then describes forms of parallelism that can be used in microprocessors and other systems. Firstly the relationship between power, computational throughput, parallelism, and supply voltage is established.
Let V be the supply voltage P be the power consumption S be the speed at which gates operate N be the extent of parallelism and T be the computational throughputFor CMOS circuits, over a reasonable range of supply voltages the gate speed depends directly on the supply voltage [WEST93]:
S prop to V (1)If the potential parallelism is fully utilised, the throughput depends on the gate speed and the parallelism:
T prop to S . N (2)If there is no overhead associated with the parallelism, for conventional CMOS power consumption depends on the square of the supply voltage and the throughput [WEST93]:
P prop to T . V^2 (3)Let us derive the relationship between P and N for constant T and variable V:
Substituting from (1) and (2) into (3):
P prop to T . ( T / N )^2 (4)Since T is constant, from (4)
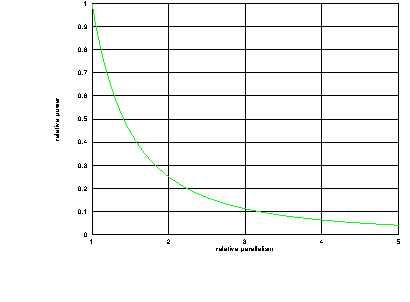
P prop to 1/(N^2) (5)So power decreases with the square of the parallelism. For example, if a processor with no parallelism is replaced by another with parallelism of two, the power consumption is reduced by a factor of four if the supply voltage is adjusted to maintain the same throughput. The overhead of the parallelism will eat in to this advantage to some extent; the additional control logic will consume power, and the utilisation of the parallelism may be incomplete. Although these effects may be quite significant in some cases they are unlikely to exceed the factor of four mentioned here.
Figure 3.1 plots the relationship derived above for parallelism between 1 and 5.
One practical disadvantage of an increase in parallelism is the resulting increase in cost, particularly as many power-sensitive embedded applications are also cost sensitive.
For most forms of parallelism circuit area increases at least linearly with the degree of parallelism (the important exception is pipelining which is discussed later). Cost depends on area, and as area increases yield decreases further multiplying the cost.
In most cases the question of what additional cost can be sustained for a particular increase in power efficiency is a matter of marketing. In some cases however a quantitative argument can be made.
Consider a system comprising a processor and a battery. If the power efficiency of the processor can be increased then a cheaper lower capacity battery could be used with the same overall system performance. If
Cp1 is the cost of the non-parallel processor and Cb1 is the cost of the battery for the non-parallel processorthen the optimum degree of parallelism, Nopt, to minimise total cost is given by
Nopt = cube_root ( 2 . Cb1 / Cp1 )This result is unappealing because it suggests that in this case even two-way parallelism is attractive only when Cb1 = 4 . Cp1. Other factors for desiring low power, such as increased battery life or reduced battery weight, are less quantifiable but may be more compelling.
The use of increased parallelism to reduce power consumption has been applied in a number of digital signal processing applications with good results.
An excellent example is the Berkeley InfoPad work [CHAN94] [RABA94] which has implemented a number of signal processing functions for a portable multimedia terminal including video decompression. These circuits incorporate substantial parallelism, allowing them to operate at reduced supply voltages and hence with increased power efficiency. Table 3.1 compares two implementations of a video decompression circuit.
Design Style Clock Frequency Supply Voltage Power Area / MHz / V / mW / mm^2 Uni-processor 8.3 3.3 10.8 72 Multi-processor 1.04 1.1 0.25 112These results show that in this special purpose processing application the use of parallelism and reduced supply voltage can lead to very great power savings. It would be a great success to achieve the same sort of savings in general purpose processors.
In the past parallelism has not been applied to general purpose processors with the objective of improving power efficiency, but it has been extensively used to improve performance and exactly the same techniques may be applied. These techniques and their applicability to low power processors are described in the remaining sections of this chapter.
Parallelism in processors may be divided into two categories:
Making parallelism visible places the duty of exploitation on the programmer rather than the processor designer. In the case of a transputer network the hardware overhead is low; the only requirement is for a number of communication channels between the processors. On the other hand the programmer's overhead is large: he must re-write his algorithms to use message-passing parallelism.
When parallelism is invisible to the programmer, code that has been written for a conventional processor can be executed unchanged on the parallel machine. The hardware takes responsibility for detecting and exploiting the available parallelism; consequently the processor design is more complex.
Some examples of programmer-visible and invisible parallelism are show in table 3.2.
Fully Visible Visible only to Invisible compiler Message passing multiprocessors Vector processors Pipelined processors Shared memory multiprocessors VLIW processors Superscalar processorsWith all of these approaches the potential for increased power efficiency is determined in the same way by the degree of parallelism achieved, as explained in section 3.1. SCALP uses parallelism that is generally invisible to the programmer and so this chapter focuses on pipelining and superscalar execution.
The following two sections describe the implementation of conventional pipelined and superscalar processors, and it will be seen that particularly in the case of superscalar processors the implementation complexity is high. SCALP finds a compromise that can maintain the programming simplicity of programmer-invisible parallelism and bring some of the hardware simplicity of programmer-visible parallelism.
Pipelining is a particularly attractive form of parallelism because it does not carry the same area overhead that other forms do. This section seeks to find out what degree of pipeline parallelism can be obtained reasonably in a microprocessor and what cost is associated with its implementation.
The degree of parallelism depends on two factors:
Pipelining is possible in RISC microprocessors as a result of their regular instruction sets. In these processors all instructions follow virtually the same sequence of micro-operations[FOOTNOTE]:
[FOOTNOTE] branch instructions excepted.
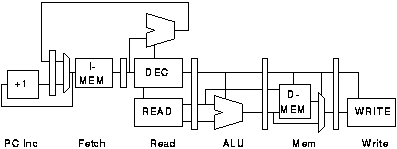
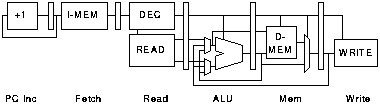
There are a number of ways in which these operations can be organised into pipeline stages. The particular organisation chosen will depend on the relative speeds of each of the operations. Here we consider a six-stage organisation where each of these operations is carried out in a separate pipeline stage, with the exception of instruction decode and register read which can be carried out together[FOOTNOTE]; other pipeline organisations are considered later.
[FOOTNOTE] The positions of the source register specifiers in a RISC instruction are fixed so these registers can be read while the rest of the instruction is decoded.
The structure and timing of this pipeline are shown in figures 3.2 and 3.3. In figure 3.3 each column represents a clock period and each row a pipeline stage; the numbers indicate which instruction is active in each stage at each time. It would appear that this organisation offers 6 fold parallelism which has a potential 36 fold power saving. In fact a non pipelined processor would not have to execute exactly 6 times as many cycles as the pipelined processor because many instructions do not need to perform every operation; only loads and stores access the memory, compares and stores do not write a result to the register bank, branch instructions do not access the register bank etc.
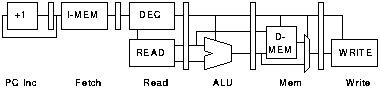
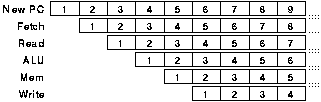
Furthermore there are two particular problems that could reduce the performance of the pipelined processor: branches and dependencies. The following sections explain these problems and the mechanisms used to mitigate their effects; afterwards table 3.3 quantifies the parallelism that is obtainable.
Branch instructions do not work well in simple pipelines because until they have computed their target address instructions from the target address cannot be fetched and begin execution. In a processor with a single adder branch target addresses take the path highlighted in figure 3.4. The timing of this organisation is shown in figure 3.5; instruction 3 is a branch to instruction 10. Two instructions (shaded) must be discarded after the branch is fetched.
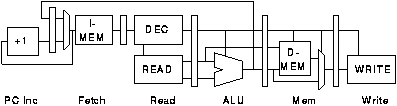
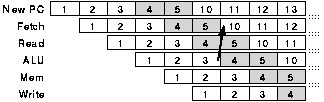
If a dedicated adder is available for branch target computation and branch instructions can be decoded quickly the approach shown in figures 3.6 and 3.7 can be used. In this case only one cycle is lost.
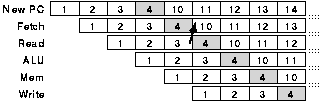
Two principle techniques may be used to reduce the impact of this effect on the pipeline's performance. Firstly branch delay slots can be used. In this system the instructions in the locations following the branch instructions are fetched and executed irrespective of whether the branch is taken. The compiler has to find instructions that can be placed here to do useful work. [HENN90] claims that it is able to do so usefully about half of the time for the first slot and significantly less of the time for any second or subsequent slots (see appendix A).
The second approach is to use branch prediction. In this system the branch target is guessed and instructions from the target are fetched and executed. The true branch target is computed concurrently. If the branch turns out to have been wrongly predicted the speculatively fetched instructions are cancelled. The prediction scheme may be a simple one such as "predict not taken" where instructions are always fetched from beyond the branch target or a more complex dynamic scheme based on the instruction's previous behaviour. The effectiveness of branch prediction depends on the complexity of the branch history mechanism but correct prediction rates of around 90% have been reported [HENN90].
Consider the following instruction sequence:
R1 := R2 + R3 R4 := R1 + R5Note that the second instruction uses the result of the first instruction as an operand. This is referred to as a "read after write" or RAW dependency.
In the simple pipeline shown in figure 3.2 this instruction sequence would execute wrongly; when the second instruction read R1 from the register bank it would read the value of R1 existing before the first instruction executed.
There are three solutions to this problem:
In practice only the third of these techniques is used in synchronous processors with this type of pipeline; the others are mentioned here because they are of interest later in the cases of asynchronous and superscalar processors.
The necessary forwarding busses for this pipeline are shown in figure 3.8. In terms of control, the processor has to record the destination of each previous instruction that is still in the pipeline (two in this case). These destination register numbers are compared with the source register numbers of the instruction being issued. Each possible match activates one of the forwarding paths (figure 3.9).
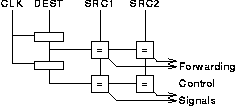
Note that when the result of a load is used by the following instruction forwarding is not possible; in this case the pipeline must be stalled for one cycle or the next instruction must be prohibited from using this register.
With the exception of the load instruction, in this simple synchronous pipeline the addition of forwarding paths means that RAW dependencies have no effect on performance. This is in contrast to superscalar processors, described in the next section, and most existing asynchronous processors.
The effective parallelism obtained in the 6 stage pipeline with each of these factors taken into account is shown in table 3.3[FOOTNOTE].
Execution Relative Cycles Parallelism Non-pipelined processor 473 1.00 Perfect pipeline, no stalls 100 4.73 As above but stalling when a load result is used by the following instruction (23 % of loads) 104 4.54 As above and allowing for stalls due to branches: Single adder 132 3.58 Dedicated branch adder 118 4.00 Dedicated branch adder and branch delay slot, filled usefully 48 % of the time 111 4.24 Dedicated adder and branch prediction, 90 % of predictions correct, 90 % of branches cached 109 4.34
Type Count Branch 14 Load 18 Store 8 Compare 3 Others 57 Total 100[FOOTNOTE] The instruction mix used is shown in table 3.4. This and other statistics from [HENN90] (see appendix A).
Table 3.3 shows that the greatest parallelism achievable with the pipeline described is 4.34; this could be used to give a power saving of about 19 times compared with the non-pipelined processor.
Shorter pipelines are worthwhile when some operations take much longer than others. The ARM2 processor was designed for use without a cache memory and its cycle time matches the dynamic RAM to which it was interfaced. The cycle time of this RAM is relatively long so the processor merges the register read, ALU and register write operations into one pipeline stage. As a consequence there is no need for any forwarding mechanism.
When the desired performance or power efficiency exceeds that which can be achieved with the type of pipeline described above it is necessary to consider using a longer pipeline where each stage performs a simpler operation. To build a longer pipeline it is necessary to find a way of subdividing the internal structure of the stage that limits overall pipeline throughput. This probably means either the memory access cycles (instruction fetch and load/store) and the ALU.
Subdivision of these stages is likely to be difficult and costly in terms of area. More importantly the longer pipeline will worsen the problems caused by branches and dependencies; for example if the ALU is pipelined then forwarding is not possible between one instruction and the next so the pipeline will have to stall more often.
At this point the designer must consider other forms of parallelism. One possibility is superscalar execution which is considered next.
The evolution of conventional RISC processors progressed from pipelined processors to so-called Superscalar processors. Superscalar processors contain multiple parallel pipelined datapaths sharing a single global register bank. They aim to fetch several instructions at a time from memory and issue one to each of the pipelines. They do this in a way that does not change the programmer's model of the processor: the result of the program must be the same as would be obtained with a single pipeline. Interactions between instructions must be detected and dealt with by the hardware.
There are many ways in which superscalar processors can be organised. One structure is shown in figure 3.10. This is a symmetrical arrangement where two pipelines of the sort shown in figure 3.2 are combined. A global register bank is shared by the two pipelines; it has 2 write ports and 4 read ports.
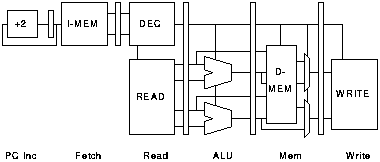
Ideal code could execute on this processor with twice the degree of parallelism that it would obtain on a single pipeline machine. This parallelism could be used to provide a four-fold power saving. Unfortunately real code does not match this ideal.
The realisable parallelism in a superscalar processor is limited by the same two factors that limit pipeline performance: branches and dependencies.
This section focuses on how these two problems affect this processor and how their effects can be mitigated. The answer is that good performance is possible but complex logic is required to control how and when instructions are issued.
As in the pipelined processor forwarding mechanisms can be used to move results within and between the pipelines; an arrangement of forwarding paths for the processor of figure 3.10 is shown in figure 3.11.
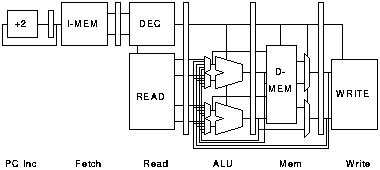
Because of the increased complexity of the processor the number of forwarding paths is increased. Each ALU input must select between the register bank output and four forwarding paths. To control these forwarding paths the destination of the last two instructions in each pipeline must be stored and compared with each operand of each instruction being issued. This requires 16 register specifier comparators compared with the 4 required in the single pipeline.
Unfortunately despite the increased complexity of the forwarding logic, whereas in the pipelined processor the forwarding paths solved nearly all RAW dependencies, in the superscalar processor many dependencies have to lead to pipeline stalls. Consider this sequence:
R1 := R2 + R3 R4 := R1 + R5Because of the RAW dependency between these instructions they cannot be issued at the same time. The first may be issued but the second cannot be issued until the next cycle[FOOTNOTE]. Detecting these dependencies requires that the destination register of the first instruction in the decoder is compared with the source registers of the second instruction. Any match indicates that the pipeline must be stalled.
[FOOTNOTE] If the ALU is not the processor's critical path, then it may be possible for results computed by an ALU in one pipeline to be forwarded to another pipeline to be used in the same cycle. This technique is applied in the Sun SuperSPARC processor [SUN92] but is not considered further here.
This restriction significantly limits the effective parallelism of a superscalar processor of this type. This limit may be overcome but it requires yet more complexity in the instruction decoding and issuing. One technique that may be used is out of order issue. Consider this sequence:
R1 := R2 + R3 R4 := R1 + R5 R6 := R7 + R8 R9 := R6 + R10Here the second instruction depends on the first instruction and the fourth instruction depends on the third instruction. In order to fully occupy two pipelines these instructions can be issued out of order: in the first cycle the first and third instructions are issued, and in the second cycle the second and fourth instructions are issued.
By using out of order issue the utilisation of the available parallelism in a superscalar processor is significantly increased. Unfortunately another form of dependency introduces another limit. The following code sequence illustrates a write after read (WAR) dependency:
R1 := R2 + R3 R4 := R1 + R5 R5 := R7 + R8 R9 := R5 + R10The first and second instructions cannot be issued together because of a RAW dependency between them. However the first and third instructions are independent and so it would be desirable to issue them together. Unfortunately the third instruction modifies R5, one of the registers that is used as an operand by the second instruction, and so it cannot be issued before it. This is a WAR dependency.
WAR dependencies can be avoided using a technique called "register renaming". Register numbers from instructions are considered as "logical" register numbers and are mapped to the "physical" registers during decoding. In this code sequence, the references to R5 in the third and fourth instructions are made to a "renamed" version of R5 which is actually a different physical register:
R1 := R2 + R3 R4 := R1 + R5 R5a := R7 + R8 R9 := R5a + R10With this re-arrangement the first and third instructions can be issued together, and the second and fourth instructions can be issued together in the next cycle.
To support out of order issue and register renaming the organisation of the superscalar processor must be significantly changed. One possible organisation from [JOHN91] is shown in figure 3.12. The operation of this processor is as follows:
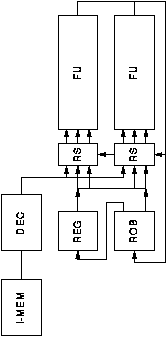
The same fundamental problems affect branch instructions in a superscalar processor as in a pipelined processor: during the branch latency useful instructions cannot be fetched. In a superscalar processor this problem is multiplied: the number of cycles of the branch latency remains the same, but the number of potential instructions that have been lost grows.
Branch prediction may be used to ensure that useful work is done during the branch latency. When a branch has been mispredicted it is necessary to undo the effect of all speculatively executed instructions. This is one of the functions of the reorder buffer; results are not released from the reorder buffer to the register file until their execution has been confirmed.
[JOHN91] makes a very thorough study of the performance of superscalar processors for general purpose applications with and without various architectural features including out of order issue, register renaming, and branch prediction (see appendix A). Table 3.5 summarises his conclusions about the importance of the various features.
Feature Performance advantage resulting from adding the given feature to a processor that already has all of the other features Out of order issue 52 % Register Renaming 36 % Branch Prediction 30 % Four instruction decoder (as opposed to a two instruction decoder) 18 %It can be seen that in order to obtain reasonable parallelism from a superscalar processor it is necessary to implement most or all of these complex features; without them the potential parallelism simply is not achieved. Yet their implementation is complex and consequently highly power consuming.
It is interesting to quote Johnson's observations about the complexity of superscalar processor control logic:
" 9.1.4 The Painful Truth
For brevity, we have examined only a small portion of the superscalar hardware: the portion of the decoder and issue logic that deals with renaming and forwarding. This is a very small part of the overall operation of the processor. We have not begun to consider the algorithms for maintaining branch-prediction information in the instruction cache and its effect on cache reload, the mechanisms for executing branches and checking predictions, the precise details of recovery and restart, and so on. But there is no point in belaboring the implementation details. We have seen quite enough evidence that the implementation is far from simple.
Just the hardware presented in this section requires 64 5-bit comparators in the reorder buffer for renaming operands: 32 4-bit comparators in the reservation stations for associatively writing results: 60 4-bit comparators in the reservation stations for forwarding: logic for allocating result tags and re-order-buffer entries: and a reorder buffer with 4 read ports and 2 write ports on each entry, with 4 additional write ports on portions of each entry for writing register identifiers, results tags, and instruction status. The complexity of this hardware is set by the number of uncompleted instructions permitted, the width of the decoder, the requirement to restart after a mispredicted branch, and the requirement to forward results to waiting instructions.
If the trend in microprocessors is toward simplicity, we are certainly bucking that trend. "
The preceding section shows that the parallelism obtainable from superscalar execution is desirable but its cost is too high. This section considers ways in which the superscalar control problem can be simplified through changes to the instruction set architecture.
The role of the instruction decoding and issuing logic and the reservation stations in a superscalar processor can be thought of as translation. In the input language the flow of data between instructions is described by means of register identifiers; in the output the same information is described by renamed register specifiers and forwarding control information. It is interesting to consider encoding some form of this translated information directly into the instructions.
There are a number of problems with this idea. If the renamed registers and forwarding information are encoded directly it is not possible to use the same code on processors with different organisations. It should also be noted that the output of the translation process in the conventional processor is not a function of only the static program but also its dynamic behaviour: a particular sequence of instructions may be translated into different forwarding information depending on which branch instruction lead to its execution.
Despite these problems it is possible to find compromise encodings that require less processing by the decoder and issuer than the conventional system using register numbers alone. SCALP uses such a technique called explicit forwarding which is described in chapter 5.
An alternative method for simplifying the superscalar organisation is to adopt the VLIW (very long instruction word) approach where each instruction specifies one operation for each of the functional units. This technique has not been considered for SCALP because it leads to a substantial decrease in code density; whenever the compiler is unable to find an operation for a functional unit that part of this instruction is unused. Chapter 2 explained that code density is important to SCALP for low power operation.
The preceding sections have mentioned the importance of branch prediction to obtain high levels of parallelism in pipelined and superscalar processors. The parallelism obtained through branch predication can be used to increase power efficiency.
On the other hand it can be argued that when branch prediction is wrong energy has been wasted in partially executing the wrongly predicted instructions. To obtain the maximum power efficiency there must be a balance between these two factors.
This is an example of a general question concerning the balance between speculation and concurrency. Another example occurs in the design of an equality comparator: the minimum number of transitions occur if the comparator operates serially, stopping as soon as a mismatch is detected. On the other hand a parallel implementation that compares all bits simultaneously will operate more quickly allowing for lower voltage operation.
Whether branch prediction is power efficient can be computed as shown in table 3.6[FOOTNOTE]. This table relates to the pipelined scheme described in section 3.5.
With Branch Without Branch Prediction Prediction Relative parallelism 4.34 4.00 Power due to parallelism 0.053 0.063 Relative throughput 1.03 1.00 Power due to throughput 1.03 1.00 Overall Power 0.055 0.063It can be seen that the increased parallelism due to branch prediction leads to a power saving of 16 %, and on the other hand the power wasted on speculatively executed instructions amounts to 3 %. There is therefore a net power saving of 13 % due to branch prediction.
[FOOTNOTE] Note that this excludes the power costs of implementing the branch prediction function itself.