Having given the motivation for SCALP in the previous chapters, this chapter describes the SCALP architecture and explains how it meets the objectives that have been set out.
To summarise these objectives:
For high power efficiency we desire high code density, parallelism and asynchronous implementation.
To obtain high code density:
(1) Use variable length instructions (section 2.1.1).
(2) Have the minimum possible redundancy in the instructions (section 2.1).
(3) Reduce the contribution to code size of register specifiers by exploiting the fact that the result of one instruction is typically used very soon by a following instruction (section 2.1.2).
To obtain parallelism:
(4) Employ pipelining (section 3.5).
(5) Use multiple functional units (section 3.6).
(6) Issue multiple instructions out of order (section 3.6.1).
(7) Try to reduce the complexity of the superscalar instruction issuer (section 3.6.3).
To permit asynchronous implementation:
(8) Adapt the architecture so that conditional forwarding may be used within and between the pipelines (section 4.2.2).
(9) Provide decoupling between functional units (section 4.2).
Also:
(10) Have a HALT instruction (section 4.1.4).
(11) Have instructions that operate on quantities narrower than the full width of the datapath (section 2.2).
SCALP's main architectural innovation is its lack of a global register bank and its result forwarding network. This approach is motivated by points (3), (7), (8), and (9) above.
Most SCALP instructions do not specify the source of their operands and destination of their results by means of register numbers. Instead the idea of explicit forwarding is introduced. Each instruction specifies the destination to which its result should be sent. That destination is the input to another functional unit where the instruction that uses that result will subsequently execute, consuming the value.
Instructions do not specify the source of their operands at all; they implicitly use the values provided for them by the preceding instructions.
SCALP does have a register bank; it constitutes one of the functional units. It is accessed only by read and write instructions which transfer data to and from other functional units by means of the explicit forwarding mechanism.
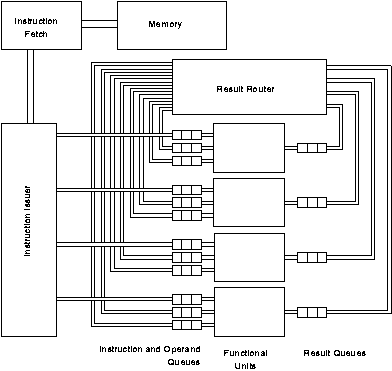
Figure 5.1 shows the overall organisation of the processor.
Several instructions are fetched from memory at a time. Each instruction has a small number of easily decoded bits that indicate which functional unit will execute it[FOOTNOTE]. The instruction issuer is responsible for distributing the instructions to the various functional units on the basis of these bits.
[FOOTNOTE] Note that the instructions are statically allocated to functional units. If there is more than one functional unit that is capable of executing a particular instruction, one must be chosen by the compiler. This helps to simplify the instruction issuer and is essential to the explicit forwarding mechanism. It may be slightly detrimental to performance if the compiler is not able to predict accurately which functional units will be most busy.
Each functional unit has a number of input queues: one for instructions and one for each of its possible operands. An instruction begins execution once it and all of its necessary operands have arrived at the functional unit.
The functional unit sends the result along with the destination address to the result routing network. This places the result into the appropriate input queue of another functional unit.
Consider the following code:
a = b+c; d = 10-a;If we assume that variables b and c are initially in memory, a conventional architecture would compile this to the following code:
load rb,[b_addr] load rc,[c_addr] add a,b,c sub d,#10,aSCALP would treat the code as follows: it observes that the loaded values are used only by the following addition and that the result of the addition is used immediately by the subtraction. The compiler will be able to tell whether variable a will be read again before it is next written to. If it is not then the following code is possible:
load [b_addr] -> adder_input_a load [c_addr] -> adder_input_b add -> subtracter_input_a sub #10 -> ...This code uses the same number of instructions as the conventional architecture, yet each instruction can be significantly smaller. The instructions do not need to specify any input operands and the destinations are specified simply by a functional unit input code, which can be encoded in only a few bits.
The advantages of explicit forwarding are as follows:
One way of viewing the result routing network and the associated queues is as an additional level in the processor's memory hierarchy. In a conventional processor the register bank is used for both short term storage from one instruction to the next[FOOTNOTE] and for medium term storage of local variables. In SCALP, the register bank is still used for medium term storage of local variables but the result routing network and associated queues are used for short term storage between instructions.
[FOOTNOTE] In fact in conventional processors the register bank is not used for short term storage between instructions; the forwarding busses are. However the programming model makes it appear that the register bank is being used, and the values will be written into the register bank even when it is not necessary.
The fifo queues associated with each functional unit input make it possible to use explicit forwarding to transfer values between instructions that may not be immediately adjacent, as was the case in the earlier example. A simple example is the following code that increments two memory locations:
LOAD -> alu LOAD -> alu ADD #1 -> store ADD #1 -> store STORE STOREHere a form of software pipelining has been applied to reduce the number of data dependencies in the code, permitting faster execution.
There are some superficial similarities between the SCALP approach and dataflow computing. In particular it is possible to describe SCALP programs by means of dataflow graphs such as figure 5.2. This similarity is only superficial however; flow of control in SCALP is determined by a conventional control driven mechanism, not a data driven mechanism.
Figure 5.2 shows a dataflow diagram for a simple SCALP program to sum the values in an array. The left hand loop generates a sequence of addresses; in the middle a load instruction reads the array value; at the right hand side a loop sums the loaded values. The code listing is shown alongside.
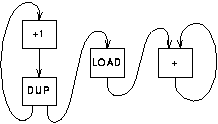
L1: ADD 1 -> movea DUP -> alua, mema LOAD -> alub ADD -> alua BR L1The basic execution model allows each result to be used by only one following instruction. This is sufficient in very many cases. When a result needs to be used more than once two possibilities are available to the programmer:
The program shown in figure 5.2 makes use of a duplicate instruction.
Analysis of SPARC code carried out for [ENDE93] (see appendix A) measured the number of times that each instruction result is used. This is summarised in table 5.1 and shows that around two thirds of instruction results are used exactly once, and hence could make use of explicit forwarding without using a duplicate instruction.
Number of uses Proportion of results 0 17 % 1 64 % 2 11 % 3 4 % 4 2 % >4 2 %One way of viewing the instruction and operand queues is as reservation stations. The difference is that in SCALP the instructions are issued from the queues in the same order that they arrive. Furthermore operands must arrive in the correct order to match their instructions; this is guaranteed by the structure of the code.
[JOHN91] (see appendix A) considers the possibility of in-order issue to functional units from reservation stations and concludes that it has only a small detrimental effect on performance compared with out of order issue from the reservation stations:
" 7.1.3 A Simpler Implementation of Reservation Stations
...each reservation station can issue instructions in the order that they are received from the decoder. Instructions are issued in order at each functional unit, but the functional units are still out of order with respect to each other, and thus the processor still performs out of order issue. The advantage of this approach is that each reservation station need only examine one instruction to issue - the oldest one. .... Also, ... the reservation station can be managed as a first in first out queue.
The performance advantage of out of order issue at the reservation stations is negligible in some cases. Across the entire range of reservation station sizes [1 to 16 entries], the biggest difference in average performance between the two approaches is 0.6 % for a two instruction decoder and 2 % for a four instruction decoder. "
A number of questions may be asked about the safety of the proposed architecture:
The answers are that in the first two cases the processor will deadlock. In the third case the behaviour will be nondeterministic.
Note that all three cases represent programming errors. Correctly constructed programs should not exhibit any of these code sequences.
In the case of the deadlock problems, the Fred architecture (see section 4.4) has the same situation in the case of its memory access decoupling. Fred chooses to detect any illegal instruction sequences in the instruction issuer and raise an exception. Using this approach in SCALP would require a number of up/down counters and comparators in the instruction issuer and would both complicate and slow down the issuing process. In view of this SCALP chooses another approach. Deadlocks are allowed to occur and are detected by means of a watchdog timer associated with for example the instruction fetch logic. In the event of a watchdog timer timeout the processor is reset and restarts from an exception vector with empty queues. If necessary a mechanism could be provided to store a copy of the program counter value at the time when the reset occurred so that the system software could identify the faulty code.
The non-deterministic instruction sequences are more interesting. At first sight it may seem that these sequences also represent programming errors and should be illegal. Unfortunately some apparently useful program constructs lead to this form of non-determinism. Consider the following code sequence:
LOAD -> alu ADD -> xyz READ REGISTER -> alu SUB -> pqrThe effect that is wanted here is that the result of the load instruction is sent to the ALU where it is used by the following ADD instruction, and that the result of the read register instruction is sent to the ALU where it is used by the SUB instruction.
Unfortunately one possible sequence of events in an asynchronous implementation is the following:
This is not the desired behaviour, yet the original code sequence seems to be a useful one.
It should be noted that there are many similar situations where this problem does not occur. For example instructions that are executed by the same functional unit may not overtake each other. The routing network also guarantees that two values sent between the same pair of points will reach their destination in the same order that they left their source. Consequently the following code sequence is legal:
LOAD -> alu ADD -> xyz LOAD -> alu SUB -> pqrOften the order of the instructions will be enforced by data dependencies between the instructions. Consider the following sequence:
LOAD -> alu ADD -> regd WRITE REGISTER READ REGISTER -> alu SUB -> pqrHere the register read must execute after the register write (even if a different register is being accessed). The register write is dependent on the result of the add which in turn depends on the load. It is therefore impossible for the result of the register read to reach the ALU before the result of the load.
It can be argued that when this problem occurs it indicates that the code is not written in a particularly parallelisable way, or that the processor does not have the right balance of functional units. For example in the faulty example presented above the code makes greater use of the ALU than of the other functional units, making it a bottleneck. If two ALUs were present the code would operate more efficiently and without any problems of determinism. In this case the program would be as follows:
LOAD -> alu_1 ALU_1:ADD -> xyz READ REGISTER -> alu_2 ALU_2:SUB -> pqrDespite this there are situations where non-determinism needs to be eliminated. There are two approaches.
Firstly a sequencing instruction is provided. Two operands are sent to the move unit where they arrive on different input ports. The seq instruction, which is executed by the move unit, sends the two values to their ultimate destination in a defined order. For example:
LOAD -> movea READ REGISTER -> moveb SEQ -> alu ADD -> xyz SUB -> pqrAlternatively the code may be re-ordered to introduce new dependencies, ensuring a fixed execution order. For example this code
READ REGISTER -> load address READ REGISTER -> alu LOAD -> write data ADD -> write data WRITE REGISTER WRITE REGISTERmay be re-written as
READ REGISTER -> load address LOAD -> write data WRITE REGISTER READ REGISTER -> alu ADD -> write data WRITE REGISTERThe disadvantage of this second approach is that it tends to serialise the code, reducing the potential parallelism.
To help the programmer, the scaSIM simulator (see section 6.2) detects any non-deterministic sequences and produces an error message.
There are two other features of the instruction set that increase power efficiency: variable length instructions and variable width operations.
The format of a SCALP instruction is shown in figure 5.3. The instruction comprises 4 or 5 parts: a functional unit identifier, a destination address, an opcode whose meaning is specific to the functional unit, a width bit, and an optional immediate value.

The width bit indicates whether the instruction operates on 32 bit or 8 bit data. Power is saved by activating only a quarter of the datapath for 8 bit operations.
Making the immediate value optional increases the code density as many instructions do not need an immediate operand. This makes the instruction format variable length. As was mentioned in section 2.1.1 variable length instructions potentially make instruction issue more difficult in a superscalar processor. SCALP tries to reduce this effect as follows:
This section describes a proposed instruction set for a SCALP processor. This instruction set is used for the examples in this chapter and is implemented in the next chapter. However it should be noted that the SCALP principles described in the preceding sections need not apply only to this instruction set; in fact this instruction set has been chosen as just about the simplest SCALP instruction set possible and so has some weaknesses.
There are five functional units:
There is a total of 8 operand queues (alua, alub, regd, mema, memd, movea, moveb, brc) which can be encoded using 3 bits.
Move unit and register bank instructions have a fixed length of 12 bits, as shown in figures 5.4 and 5.5.
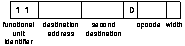
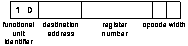
Other instructions can be either 12 or 24 bits long. In the case of 24 bit instructions the additional bits form an immediate value used by the instruction; all of the control information is contained in the first 12 bits. The formats of the ALU, load/store and branch instructions are shown in figures 5.6, 5.7, and 5.8.



The instruction stream is divided into blocks of 12 bits, referred to here as "chunks", each of which is either an instruction chunk or an immediate chunk. Five of these chunks are then placed together into a 64 bit "FIG" (Five Instruction Group) (figure 5.9). The five chunks use 60 of the 64 bits. The additional 4 bits form a control field that encodes which of the five chunks is an immediate and which is an instruction[FOOTNOTE]. As was noted in section 2.1.1, when carrying out superscalar instruction issue with variable length instructions it is essential to be able to tell where each instruction starts and finishes. The control field has this effect.
[FOOTNOTE] Only four bits are needed because not all possible combinations of immediate and instruction chunks are possible within the FIG; two immediate chunks may never be adjacent to each other.

Branch target addresses are specified by giving the address of the FIG containing the target and then giving the chunk number of the target instruction within the FIG.
There are two particular reasons why this scale of organisation has been chosen. Typically approximately one instruction in five is a branch and one instruction in five is a load or store. If more than five-fold parallelism is required then it becomes necessary to execute more than one load or store instructions or more than one branch instruction concurrently. This adds extra complexity which this simpler architecture avoids.
The instruction set is summarised in table 5.2. d indicates a result destination (i.e. a functional unit input queue), bd indicates a boolean destination, [i] an optional immediate value and i a compulsory immediate value. t indicates a branch target address.
Instruction Functional Unit Operation DUP -> d1, d2 MOVE Duplicate SEQ -> d MOVE Sequence CMOVE -> d MOVE Conditional Move MVLINK -> d MOVE Move result of last branch and link READ n -> d REG Read register WRITE n REG Write register ADD [i] -> d ALU Addition SUB [i] -> d ALU Subtraction RSB i -> d ALU Reverse subtract NEG -> d ALU Negate OR [i] -> d ALU Logical OR AND [i] -> d ALU Logical AND XOR [i] -> d ALU Logical XOR CMPEQ [i] -> bd ALU Compare for equality CMPLT [i] -> bd ALU Compare for less than CMPLTEQ [i] -> bd ALU Compare for less than or equal MOV i -> d ALU Move immediate MKIMM i -> d ALU Build large immediate value from 12-bit chunks LOAD [i] -> d LD/ST Load STORE [i] LD/ST Store BR t BRANCH Unconditional branch BRT t BRANCH Branch if true BRF t BRANCH Branch if false BRL t BRANCH Branch and Link BRC BRANCH Computed Branch HALT BRANCH Halt
The previous sections have described the SCALP architecture and instruction set in terms of their hardware-related characteristics such as code density and suitability for simple asynchronous implementation. The purpose of this section is to consider the architecture from a software viewpoint and to ask whether SCALP makes a good programming target.
Specifically there two questions that must be resolved:
This section tries to address these questions by considering an example program and showing how it can be translated to the SCALP instruction set. The program is small but it illustrates the necessary points. It is a function from a graphics program that takes the (x,y) coordinates of the vertices of a triangle abc. It executes the following function
if (bx-ax)*(cy-ay) > (cx-ax)*(by-ay)
then
/* do nothing, order OK */
else {
swap(bx,cx);
swap(by,cy);
}
which first checks whether the triangle is constructed in a clockwise or anti-clockwise direction. If the triangle is constructed anti-clockwise the coordinates of b and c are exchanged to make it clockwise. An implementation of the function in a conventional register-based instruction set (based on the ARM instruction set) is shown below.
MK_CLOCKWISE: LOAD RBX,[bx] LOAD RAX,[ax] SUB RP,RBX,RAX # compute bx-ax LOAD RCY,[cy] LOAD RAY,[ay] SUB RQ,RCY,RAY # compute cy-ay MUL RR,RP,RQ # compute (bx-ax)*(cy-ay) LOAD RCX,[cx] SUB RS,RCX,RAX # compute cx-ax LOAD RBY,[by] SUB RT,RBY,RAY # compute by-ay MUL RU,RS,RT # compute (cx-ax)*(by-ay) CMP RR,RU # (bx-ax)*(cy-ay) > (cx-ax)*(by-ay) ? BRGT Rlink # return if order is OK STORE RBX,[cx] # store b and c swapped STORE RCX,[bx] STORE RBY,[cy] STORE RCY,[by] BR Rlink # returnNote that it is assumed that the coordinates are initially in memory and must be loaded into registers. The function consists of 19 instructions totalling 608 bits.
One simple scheme for SCALP code generation is to take a conventional program such as the above and to replace each instruction with a sequence of register read instructions to fetch operands, an operate instruction, and a register write instruction to store the result. This scheme is clearly inefficient since it makes no use of the explicit forwarding mechanism, but it has the advantage of being able to encode any program without needing duplicate or sequence operations or other transformations to ensure determinism. This scheme can be used to give a worst case measure of SCALP code complexity. In the case of this example the SCALP program would have 50 instructions including 12 writes and 19 reads, totalling 640 bits - more than the conventional program.
A more efficient translation will make use of the explicit forwarding mechanism when appropriate dataflow exists between the instructions. When explicit forwarding cannot be used the translation can fall back to the register-based mechanism described above.
An initial dataflow-based translation to SCALP code gives the following as yet unsatisfactory program (note that for the purpose of this example the SCALP instruction set has been extended to include a multiply instruction):
MK_CLOCKWISE: MVLINK -> brc # store return address LOAD [bx] -> alu_a LOAD [ax] -> alu_b SUB -> mul_a # compute bx-ax LOAD [cy] -> alu_a LOAD [ay] -> alu_b SUB -> mul_b # compute cy-ay MUL -> alu_a # compute (bx-ax)*(cy-ay) LOAD [cx] -> alu_a LOAD [ax] -> alu_b SUB -> mul_a # compute cx-ax LOAD [by] -> alu_a LOAD [ay] -> alu_b SUB -> mul_b # compute by-ay MUL -> alu_b # compute (cx-ax)*(by-ay) CMPGT -> br_cond # (bx-ax)*(cy-ay) > (cx-ax)*(by-ay) ? BRT DONE LOAD [bx] -> st_data # swap bx, cx LOAD [cx] -> st_data STORE [cx] STORE [bx] LOAD [by] -> st_data # swap by, cy LOAD [cy] -> st_data STORE [cy] STORE [by] DONE: BRCThis program suffers from the following problems:
Both of these problems are addressed in the following version of the code (| indicates changed lines). This reorders the early part of the calculation so that the ax and ay operands are duplicated after they have been loaded, avoiding two loads. In addition the multiply instructions are repositioned so that their results go to the correct destination instructions.
MK_CLOCKWISE: MVLINK -> brc # store return address LOAD [bx] -> alu_a | LOAD [ax] -> move_a | DUP -> alu_b, alu_b SUB -> mul_a # compute bx-ax | LOAD [cx] -> alu_a | SUB -> mul_a # compute cx-ax LOAD [cy] -> alu_a | LOAD [ay] -> move_a | DUP -> alu_b, alu_b SUB -> mul_b # compute cy-ay LOAD [by] -> alu_a SUB -> mul_b # compute by-ay | MUL -> alu_a # compute (bx-ax)*(cy-ay) MUL -> alu_b # compute (cx-ax)*(by-ay) CMPGT -> br_cond # (bx-ax)*(cy-ay) > (cx-ax)*(by-ay) ? BRT DONE LOAD [bx] -> st_data # swap bx, cx LOAD [cx] -> st_data STORE [cx] STORE [bx] LOAD [by] -> st_data # swap by, cy LOAD [cy] -> st_data STORE [cy] STORE [by] DONE: BRCThe remaining question is that of determinism. A simple check for possible nondeterminism is to study the source of values for each operand queue. If the source is always the same functional unit there cannot be a problem as values taking the same path through the result routing network must arrive in the same order that they left. For the move_a, mul_a, mul_b and st_data queues the source is always the same functional unit so the operand order is deterministic.
For the alu_a queue the source is normally the load unit with the exception of the first multiply instruction. For the alu_b queue the source is normally the move unit with the exception of the second multiply instruction. Can the results of the multiply instructions arrive at the ALU sooner than they should?
In the case of the alu_b queue there is no problem because the multiply instruction is itself dependent on the previous ALU result, and so cannot generate its result out of order.
In the case of the alu_a queue there is a problem. The first multiply instruction and the preceding load instruction can execute concurrently, and either could be first to write to the alu_a queue. The solution to the problem is to reorder the code slightly and introduce a SEQ instruction that guarantees the order of the resulting values, as shown in the following.
MK_CLOCKWISE: MVLINK -> brc # store return address LOAD [bx] -> alu_a LOAD [ax] -> move_a DUP -> alu_b, alu_b SUB -> mul_a # compute bx-ax LOAD [cx] -> alu_a SUB -> mul_a # compute cx-ax LOAD [cy] -> alu_a LOAD [ay] -> move_a DUP -> alu_b, alu_b SUB -> mul_b # compute cy-ay | LOAD [by] -> move_a | MUL -> move_b # compute (bx-ax)*(cy-ay) | SEQ -> alu_a SUB -> mul_b # compute (by-ay) MUL -> alu_b # compute (cx-ax)*(by-ay) CMPGT -> br_cond # (bx-ax)*(cy-ay) > (cx-ax)*(by-ay) ? BRT DONE LOAD [bx] -> st_data # swap bx, cx LOAD [cx] -> st_data STORE [cx] STORE [bx] LOAD [by] -> st_data # swap by, cy LOAD [cy] -> st_data STORE [cy] STORE [by] DONE: BRCThis final code contains 27 instructions, 42% more than the conventional code. Three of the extra instructions are DUP and SEQ instructions required because of the explicit forwarding mechanism. Four are extra load instructions in the swap code required because of the lack of a global register bank for short term storage. One is an extra instruction required because of the operation of the subroutine return mechanism.
The increase is substantially offset by the smaller size of the SCALP instructions. The total program size for the SCALP code is 346 bits, only 57% of the conventional program's size.
The code reordering and other changes to the program have affected the way in which it can be executed on a superscalar processor. Table 5.3 shows a possible occupation of functional units for the conventional program. Loads, stores and multiplies are assumed to take 3 time units, subtracts, compares and untaken branches 2 time units; these values are arbitrary but may approximate to the relative speeds of these operations in an asynchronous processor.
LOAD/ SUB/ MUL BRANCH STORE CMP LOAD RBX,[bx] * * LOAD RAX,[ax] * * LOAD RCY,[cy] SUB RP,RBX,RAX * * * LOAD RAY,[ay] * * LOAD RCX,[cx] SUB RQ,RCY,RAY * * * MUL RR,RP,RQ LOAD RBY,[by] SUB RS,RCX,RAX * * * * * SUB RT,RBY,RAY * MUL RU,RS,RT * * CMP RR,RU * BRGT Rlink * STORE RBX,[cx] BR Rlink * * * STORE RCX,[bx] * * STORE RBY,[cy] * * STORE RCY,[by] * *This shows that the total execution time for the program is 39 time units.
Table 5.4 is a similar representation for the SCALP code. Move operations take 1 time unit.
LOAD/ SUB/ MUL BRANCH MOVE STORE CMP LOAD -> alu_a MVLINK -> brc * * LOAD -> move_a * * LOAD -> alu_a DUP -> alu_b, alu_b * SUB -> mul_a * * LOAD -> alu_a SUB -> mul_a * * * LOAD -> move_a * * LOAD -> move_a DUP -> alu_b, alu_b * SUB -> mul_b * * MUL -> move_b SEQ -> alu_a SUB -> mul_b * * * * * MUL -> alu_b * * * CMPGT -> br_cond * BRT DONE * LOAD -> st_data BRC * * * LOAD -> st_data * * STORE * * STORE * * LOAD -> st_data * * LOAD -> st_data * * STORE * * STORE * *This shows that the total execution time for the program is 52 time units, 13 more than the conventional architecture. This is largely explained by the additional LOAD instructions in the swap code. Apart from this there has been virtually no loss of concurrency resulting from the introduction of the SEQ and DUP instructions or the code reordering.
While any conventional program can be translated to SCALP code using an inefficient scheme, this example has shown that an approach based on dataflow can give substantially better results. The problems of result ordering and determinism that require the introduction of DUP and SEQ instructions and other transformations are solvable and do not substantially affect the efficiency of the program in terms of code size or available concurrency between the functional units.
This example illustrates well the problems encountered in the translation of straight line code within basic blocks; however it has a relatively simple control flow structure which does not demonstrate how branches can disrupt the dataflow. In the presence of more branches there is likely to be greater reliance on the register bank.
The effect that branches can have is shown in this second example. The problem is simply to find the greatest of four values a, b, c and d:
max4(a,b,c,d) = max2(max2(a,b),max2(c,d)); max2(x,y) = if x>y then x else yOne possible conventional implementation is as follows (note that it overwrites its operands during its operation):
CMP Rb,Ra BGT L1 MOV Rb,Ra L1: CMP Rd,Rc BGT L2 MOV Rd,Rc L2: CMP Rd,Rb BGT DONE MOV Rd,Rb DONE: # result is in RdOn average each execution of this code will execute 7.5 instructions using 240 bits.
A SCALP implementation suffers from the problem that the pattern of forwarding needed depends on the outcome of the comparisons, by which time it is too late to specify the destination in the source instructions. The most efficient solution is to use the register bank for all operand communication (except compare result to branch unt) as shown in the following listing:
READ Rb -> alu_a; READ Ra -> alu_a; CMPGT -> br_cond BRT L1 READ Ra -> regd; WRITE Rb L1: READ Rc -> alu_a; READ Ra -> alu_a; CMPGT -> br_cond BRT L2 READ Rc -> regd; WRITE Rd L2: READ Rd -> alu_a; READ Rb -> alu_a; CMPGT -> br_cond BRT DONE READ Rb -> regd; WRITE Rd DONE: # result is in RdOn average each execution of this code will execute 15 instructions using 192 bits. This is twice as many instructions and 80% of the code size of the conventional code's size.
Tables 5.5 and 5.6 show functional unit usage in the same style as for the first example. For illustration the first branch is taken, the second not and the third is taken again.
SUB/ BRANCH CMP/MOV CMP Rb,Ra * BGT L1 * CMP Rd,Rc * BGT L2 * MOV Rd,Rc * CMP Rd,Rb * BGT DONE *
SUB/ BRANCH REG CMP READ Rb -> alu_a READ Ra -> alu_a CMPGT -> br_cond * BRT L1 * READ Rc -> alu_a READ Ra -> alu_a CMPGT -> br_cond * BRT L2 * READ Rc -> regd WRITE Rd READ Rd -> alu_a READ Rb -> alu_a CMPGT -> br_cond * BRT DONE *The execution time for the conventional program is 14 time units and for the SCALP program is 20 time units. Neither version exhibits any functional unit parallelism due to the tight data and control dependencies.
This second example shows that in unfavourable conditions such as the presence of many data dependent branches SCALP does best by falling back on its global register bank. In this case its code density still exceeds that of the conventional processor, and SCALP does no worse than the conventional processor at exploiting functional unit parallelism.
General results should not be implied from these very limited examples, but they are sufficiently encouraging to suggest that proceeding with the design is worthwhile.
Providing support for interrupts and exceptions is often a challenging part of the design of a processor. SCALP's asynchronous implementation and the explicit forwarding scheme make exception handling somewhat different from exception handling in a conventional architecture.
No exception handling is incorporated in the SCALP implementation described in chapter 6. This section serves to show that exception handling is not an insurmountable difficulty with the architecture.
The greatest difficulty is that the exception handler must be able to save the transient state of the main program and restore it later. In a conventional processor this is not difficult as the transient state is contained within the register bank; the exception handler simply copies the contents of the register bank to a safe area of memory. For SCALP it is necessary to save and restore the contents of the operand queues which is more difficult for the following reasons:
There are several possible solutions:
In practice some combination of these approaches would be most practical with some higher priority forms of exceptions using more additional hardware than others.
This section describes other work that proposes an alternative to the global register bank model. The transputer uses a stack model; NSR, Fred, PIPE and WM use various forms of architecturally visible queues and "Transport Triggered" processors use a form of explicit forwarding.
The stack processor is the only alternative to a global register bank that has been used in a commercial processor, namely the transputer [MITC90]. In a stack processor instruction sources and destinations are not normally specified explicitly by the instruction; rather they are implicitly taken from and returned to the top of a stack. Special operations must be provided to duplicate, delete, and reorganise the stack items. The code density advantage of this approach is discussed in section 2.1.3.
The disadvantage of the stack model is that it does not work particularly well in a parallel environment. The stack itself becomes a bottleneck that must be shared by the functional units in the same way that a global register bank would, but with the added problem of maintaining the stack pointer. Every instruction implicitly changes the stack pointer; it is hard to conceive of an implementation where these changes do not occur serially.
Some previous designs have made use of programmer-visible queues to communicate between some functional units. Typically this form of communication is restricted to the results of load operations, store data, and branch conditions as it is in these cases that the decoupling provided by the queues is most useful. Synchronous processors that have used this technique include PIPE [GOOD85] and WM [WULF88]. The technique is more natural for asynchronous processors and it is used by the NSR and Fred Processors (section 4.4) [BRUN93] [RICH92] [RICH95]. In all of these designs a global register bank is retained and used for the majority of communication. Special register numbers are reserved to refer to the queues.
Transport triggered architectures (TTAs) [CORP93] [POUN95] share with SCALP the idea of transferring values between functional units by explicitly stating the functional units concerned, rather than by using a global register bank. The Transport Triggered Architecture is also referred to as the MOVE processor because it has a single instruction which moves a value from the output of one functional unit to the input of another.
Each functional unit has a number of input registers for the various operands. One of these is designated the "trigger register". When a value is written into the trigger register the functional unit is activated and after a known number of cycles its result is written into its result register.
The principle differences between the TTA idea and SCALP are:
The designers of the TTA consider it to be an example of a processor where the compiler takes responsibility for a greater proportion of the preparation for execution than in conventional architectures. Figure 5.10, from [HOOG94], illustrates this.
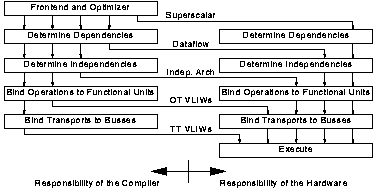
Like the TTA, SCALP makes many additional tasks the responsibility of the compiler. The compiler (or assembly language programmer) must be aware of dependencies between instructions to write SCALP code. SCALP code makes a static allocation of instructions to functional units. Like TTAs and unlike any of the other processor types in figure 5.10 SCALP code makes a static allocation of result and operand movement to particular paths within the processor.
The transport triggered architecture work is significant because a compiler has been ported to the processor and significant benchmark programs have been simulated. This is encouraging because it suggests that SCALP's execution model may also make a reasonable compiler target.