This problem will be important to us because we will often
have a continuously varying measurement which will be used to make a
classification. Thus, we will be attempting to estimate ![]() ,
where
,
where ![]() is the classification and
is the classification and ![]() is the value of the
measurement. That can be done by estimating
is the value of the
measurement. That can be done by estimating ![]() , that is the
probability distribution for the values of the measurements for each
classification, which is related to
, that is the
probability distribution for the values of the measurements for each
classification, which is related to ![]() through Bayes rule. The
estimation of
through Bayes rule. The
estimation of ![]() is one of density estimation.
is one of density estimation.
Methods of density estimation fall into two classes: parametric and non-parametric. Parametric approaches assume a particular form for the probability distribution. There are some parameters which are adjusted to make the distribution most like the data. For example, a common approach for one-dimensional data is to assume that the data comes from a normal or Gaussian distribution. This distribution is specified with two parameters, the mean and the standard deviation. It turns out that the best way to set those parameters is use the mean and the standard deviation of the data. It can be shown that these are the maximum likelihood estimates. The problem with this approach is that the assumed form of the distribution might not be appropriate for the problem.
An example of a non-parametric method is a histogram. To make a
histogram, you simply divide the region which contains the data into a
number of equal sized sections or bins; the estimate of the density for each
section is the fraction of the data which falls inside that bin. In
other words, to estimate of ![]() for any
for any ![]() , find the bin that
, find the bin that ![]() is in, say that is the
is in, say that is the ![]() th bin,
and use the estimate
th bin,
and use the estimate ![]() , where
, where ![]() is the number of data points used to make the
histogram, and
is the number of data points used to make the
histogram, and ![]() is the number of data points in the
is the number of data points in the ![]() th bin.
th bin.
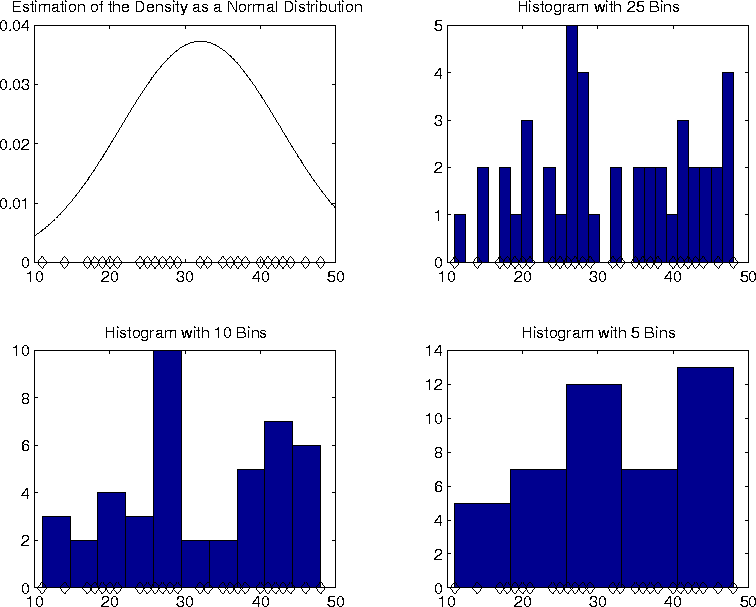
The choice of the bin size determines how smooth the data appears. If the bin-size is very small, the density will appear very spikey; if the bin size is large, important features of the data might be washed out. One of the problems with histograms is that one never knows how to set the bin size. Another problem is that they can only be used on low dimensional data.
As an example of density estimation, consider the following set of numbers:
37 28 36 42 26 27 37 48 26 19 48 42 33 38 20 11 28 40 48 28 41 44 27 46 17 28 14 44 21 48 29 35 32 14 20 43 18 25 38 24 27 43 46 24Suppose we want to model a probability distribution which may have produced the data. First, model the data as a normal distribution. The mean of the data is
To produce a histogram, divide the region which contains the data in
to a number of bins. In this case the data lies in the interval ![]() to
to ![]() . The
remaining graphs in figure
. The
remaining graphs in figure ![]() show histograms for different bin sizes. Notice that
the histograms seem to show that the distribution has two peaks. The
Gaussian approximation, misses this, of course.
show histograms for different bin sizes. Notice that
the histograms seem to show that the distribution has two peaks. The
Gaussian approximation, misses this, of course.
 |