
APT research areas
Advanced Processor Technologies
The Advanced Processor Technologies (APT) group conducts research into the design of advanced and novel approaches to processing and computation. Current projects focus on asynchronous technology and tools, novel on-chip multiprocessor architectures exploiting lightweight thread mechanisms, and hardware support for large-scale neural systems.
The group currently comprises 8 academic staff, 12 research staff, 2 technical support staff and 10 research students. It has a history of industrial collaboration, having close associations with (amongst others) ARM Limited, Inmos, Philips, Mitel, ICL, Infineon, Theseus Logic and Sun Microsystems over the past decade. The group is eager to continue working with industry in order to maximise the relevance and potential benefits of the work. In addition to collaborating with established industry the group has also been connected with the formation of a number of start-up companies including Cogency Technology, Inc., Transitive Technologies Limited and Cogniscience Limited and, recently, Silistix Limited.
The current APT research programme receives over £0.6 million per year of funding from a range of sources. The primary source of funding is the EPSRC, but the group also receives significant funding from EU programmes and from industry. The major activities of the group are detailed below.
The Amulet
Asynchronous Processors

The group has an international reputation for its work on asynchronous implementations of processor architectures, most notably the asynchronous implementations of the ARM 32-bit architecture in the Amulet series. Amulet1 was the first asynchronous implementation of a commercial 32-bit processor architecture and earned the group a BCS Award in 1995. It demonstrated that asynchronous VLSI design could scale to commercially relevant levels of complexity. Amulet2 (1996) and Amulet3 (2000) took the technology forward to demonstrate the technical advantages of asynchronous design, culminating in the integration of Amulet3 into the DRACO chip (illustrated above), a commercial telecommunications controller with a fully asynchronous processing subsystem.
SPA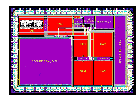 , the latest Amulet processor core
represents a break from its predecessors in that, while the
earlier processors were full-custom, manually-developed
designs, SPA was entirely synthesized using the group's
Balsa synthesis system (see below). SPA was developed
within the EU-funded
G3Card/ project
as a component on a prototype smart card chip
(illustrated), with the research objective of greatly
improving the security of the chip to non-invasive attempts
to extract secret information from it. SPA is the world's
first fully synthesized asynchronous 32-bit processor, and
the G3Card chip includes not one but two SPA cores, one
using a specially-developed secure logic technology and the
other a more conventional logic style for comparison
purposes. Synthesis enabled the two different cores to be
designed with very little additional design effort over
that required to produce a single core.
, the latest Amulet processor core
represents a break from its predecessors in that, while the
earlier processors were full-custom, manually-developed
designs, SPA was entirely synthesized using the group's
Balsa synthesis system (see below). SPA was developed
within the EU-funded
G3Card/ project
as a component on a prototype smart card chip
(illustrated), with the research objective of greatly
improving the security of the chip to non-invasive attempts
to extract secret information from it. SPA is the world's
first fully synthesized asynchronous 32-bit processor, and
the G3Card chip includes not one but two SPA cores, one
using a specially-developed secure logic technology and the
other a more conventional logic style for comparison
purposes. Synthesis enabled the two different cores to be
designed with very little additional design effort over
that required to produce a single core.
JASPA is a hardware accelerator for the Java Virtual Machine (JVM) which can be inserted as a pipeline unit in the SPA asynchronous Amulet processor to translate JVM instructions into ARM instructions at run-time.
On-Chip
Multiprocessing
The number of transistors that can be fabricated on a single integrated circuit will continue to rise towards a billion or so over the next decade. A major challenge facing the designer is to extract the maximum performance from these chips while keeping design costs under control. A promising approach is to employ a large number of relatively simple processors on a single chip.
The JAMAICA Project
The major aim of the JAMAICA project is to investigate the hardware and software technologies required to exploit the performance potential of future VLSI as the level of integration increases. The project starts from the assumption that the prospective exploitation of Instruction Level Parallelism will be limited by hardware complexity and that the future lies in closely integrated collections of CPUs which exploit parallelism at the level of lightweight threads comprising hundreds or thousands of machine instructions.
To deliver increasing performance on general-purpose applications, it is necessary to have automatic techniques to extract thread-level parallelism from programs. Such parallelisation in anything other than simple cases is limited by the capabilities of static program analysis. It is our belief that dynamic compilation techniques can provide a more flexible and more efficient way of dealing with more general programs. It is believed also that hardware support will be needed to handle lightweight threads, to provide feedback to the compilation and to support features such as speculative memory to enable compilation decisions to be rescinded.
The project is currently working with a dynamic compilation system which runs on top of a flexible instruction level architecture simulator allowing a wide range of software and hardware options to be explored.
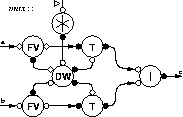 Balsa - a High-Level Asynchronous Circuit
Synthesis System
Balsa - a High-Level Asynchronous Circuit
Synthesis System
Balsa is both a framework for synthesising asynchronous (clockless) hardware systems and the language for describing such systems. The approach adopted is that of syntax-directed compilation into communicating handshaking components and closely follows the Tangram system of Philips. The advantage of this approach is that the compilation is transparent: there is a one-to-one mapping between the language constructs in the specification and the intermediate handshake circuits that are produced. It is relatively easy for an experienced user to envisage the architecture of the circuit that results from the original description. Incremental changes made at the language level result in predictable changes at the circuit implementation level. This is important if optimisations and design-tradeoffs are to be made easily and contrasts with a VHDL description in which small changes in the specification may make radical alterations to the resulting circuit.
The Balsa synthesis tool is available under GPL and is the world's leading widely-available high-level asynchronous design tool. The continuing development of Balsa is funded by the EPSRC, as is a collaborative project with Birmingham University that aims to add formal verification features to the design flow.
Layout-Sensitive Production Test
Conventional approaches to the production test of integrated circuits focus on the logical structure of the device under test. However, the likelihood of particular faults (such as a short-circuit between two wires) clearly depends on the physical proximity of particular features, and factoring knowledge of the layout of the chip into the test generation system should yield significant benefits. This work is funded by the EPSRC.
Hardware Support for Large-Scale Neural
Networks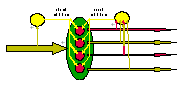
The "SpiNNaker" project has begun the development of a hardware system capable of simulating up to a billion neurons in real time. The focus of this work is "Neural Systems Engineering" - understanding how robust high-performance computing systems can be built from unreliable component neurons. Biological neural systems are examples of highly complex asynchronous systems, and there are clear opportunities to transfer the lessons from the group's extensive work on asynchronous digital systems into this new area. The work is funded partly through an EPSRC Portfolio Partenership Award and partly from Cogniscience Limited, a University spin-out company.
CADRE - Asynchronous DSP
The design for the CADRE digital signal processor (DSP) was developed by Mike Lewis in the course of his PhD and earned him a Best Paper Award at the EPSRC PREP conference. This design is now being taken forward to an implementation on silicon with the goal of demonstrating significant power savings compared with existing clocked DSPs as a result of a number of innovative architectural features that exploit its asynchronous mode of operation.
Networks-on-Chip
The DRACO chip mentioned above incorporated the world's first fully asynchronous multi-master on-chip bus, MARBLE. This work earned its designer a BCS/CPHC UK Distinguished Dissertation Award for his PhD thesis. A more advanced scheme for on-chip interconnect, "CHAIN" , forms the basis of the GALS project. CHAIN is also the core technology to be exploited by Silistix Limited and was proved on silicon in the G3Card chip (mentioned above).
The GALS Project
GALS - Globally Asynchronous Locally Synchronous - systems exploit asynchronous technology to provide a flexible interconnect fabric between clocked functional modules. This frees the designer of highly complex Systems-on-Chip (SoCs) from the combinatorial tyranny of timing closure, where in the final stages of a design the communications between every pair of modules must be checked for timing constraints. With a self-timed, correct by construction, fabric - such as is offered by CHAIN - the timing closure problem is greatly simplified. This results in lower design costs and risks and a shorter time to market.
Another aspect of on-chip communications is the provision of Quality-of-Service (QoS) communications, whereby links carrying time-critical data can have guaranteed allocated bandwidth. Techniques for achieving this at low cost on a chip are being pursued in the GALS project, which is funded by the EPSRC and is a collaborative project with Cambridge University.
Advanced Computer Arithmetic
The group has expertise in computer arithmetic, both traditional, floating-point and novel exact arithmetics. In our floating-point work we seek to achieve correct operation and correct rounding for floating-point operations such as sin(x) and log(x). Our work with floating-point arithmetic has led us to develop exact arithmetic as a way to check our results are correct. Most computer software that is used for science and engineering applications is based upon approximations - numbers are stored and processed to some fixed accuracy determined by the computer hardware. However, in long calculations, errors can grow and cause grossly erroneous results and these can be undetectable. Exact arithmetic techniques perform calculations without fixing the precision of the intermediate values and can guarantee that such errors do not occur. The consequences for engineers designing safety-critical structures such as bridges and aircraft are evident, and although it might be difficult to employ these exact techniques in production software, current results show that the techniques will have increasing utility in mathematical modelling as the size of these models increases.
Future
plans
The current overall theme of the group's research is the efficient exploitation, for computational purposes, of the ever-increasing transistor resources available on a silicon chip. We have unique capabilities in the design of asynchronous processors for high-performance low-power applications. These are ideally suited to the ubiquitous computing systems - combining sensors and ad-hoc radio networking with local processing - that will characterise pervasive computing applications over the next decade and beyond.
Contact details:
Professor Steve Furber FRS FREng email:
sfurber@cs.man.ac.uk
Professor Ian Watson FBCS email: iwatson@cs.man.ac.uk
web: http://www.cs.manchester.ac.uk/apt/